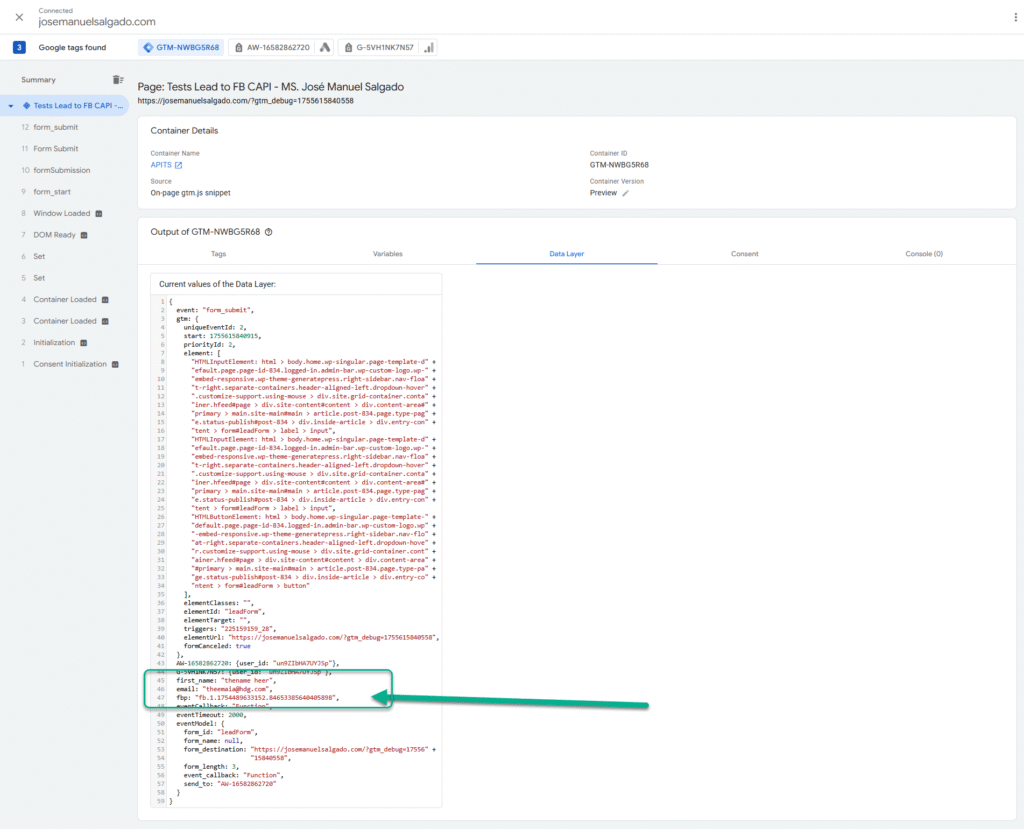
IN this article I show you how to report an OutboundClick event to Meta’s Conversions API that contains fbc and fbp for ad attribution
First, using a GTM script I scan the page for a specific domain and add fbc and fbp to the link
Example of an affiliate link:
https://freecash.com/?utm_source=customsource&sub1=customsub1
the script finds all links pointing to freecash.com and appends the fbc and fbp values taken from the cookies (which in turn were collected by GTM as container variables)
<script>
/* GTM Tag Name: "tag link" */
(function() {
var affiliateDomain = 'freecash.com';
var fbcValue = '{{fbc}}';
var fbpValue = '{{fbp}}';
function appendParamsToLink(link) {
try {
var href = link.href;
var separator = href.indexOf('?') !== -1 ? '&' : '?';
var newHref = href + separator + 'fbc=' + encodeURIComponent(fbcValue) + '&fbp=' + encodeURIComponent(fbpValue);
link.href = newHref;
} catch (e) {
console.warn('Failed to tag link:', link.href, e);
}
}
function tagAffiliateLinks() {
var links = document.querySelectorAll('a[href*="' + affiliateDomain + '"]');
for (var i = 0; i < links.length; i++) {
appendParamsToLink(links[i]);
}
}
// Run on DOM ready
if (document.readyState === 'loading') {
document.addEventListener('DOMContentLoaded', tagAffiliateLinks);
} else {
tagAffiliateLinks();
}
// Observe dynamically added links
var observer = new MutationObserver(function(mutations) {
for (var i = 0; i < mutations.length; i++) {
var mutation = mutations[i];
for (var j = 0; j < mutation.addedNodes.length; j++) {
var node = mutation.addedNodes[j];
if (node.nodeType === 1) {
var newLinks = node.querySelectorAll ? node.querySelectorAll('a[href*="' + affiliateDomain + '"]') : [];
for (var k = 0; k < newLinks.length; k++) {
appendParamsToLink(newLinks[k]);
}
}
}
}
});
observer.observe(document.body, { childList: true, subtree: true });
})();
</script>
Then a click listener sends the data to my vercel function
<script>
// This script is designed to be a Custom HTML Tag in Google Tag Manager.
// It is triggered by a "Click - Just Links" or "Click - All Elements" trigger.
// Helper function to get cookie values
var getCookieValue = function(name) {
var value = "; " + document.cookie;
var parts = value.split("; " + name + "=");
if (parts.length === 2) return parts.pop().split(';').shift();
return null;
};
// Helper function to get URL parameter values
var getUrlParameter = function(href, name) {
name = name.replace(/[\[\]]/g, '\\$&');
var regex = new RegExp('[?&]' + name + '(=([^&#]*)|&|#|$)'),
results = regex.exec(href);
if (!results) return null;
if (!results[2]) return '';
return decodeURIComponent(results[2].replace(/\+/g, ' '));
};
// Vercel function URL
var vercelFunctionUrl = 'https://123-five-gamma.vercel.app/api/everflowclicktofb';
// These variables are GTM built-in variables and will be populated at runtime.
var clickUrl = {{Click URL}};
var clickText = {{Click Text}};
// Check for a valid URL to proceed
if (clickUrl) {
// Fetch the user's IP address from a third-party service
fetch('https://api.ipify.org?format=json')
.then(function(response) {
return response.json();
})
.then(function(ipData) {
var payload = {
event_name: 'OutboundClick',
click_url: clickUrl,
click_text: clickText,
// Essential parameters for Facebook Conversions API
fbc: getCookieValue('_fbc') || null,
fbp: getCookieValue('_fbp') || null,
fbclid: getUrlParameter(clickUrl, 'fbclid') || null,
clientUserAgent: navigator.userAgent,
sourceUrl: window.location.href,
// The IP address fetched from the service
client_ip_address: ipData.ip
};
console.log("Sending payload to Vercel function:", payload);
// Now, send the complete payload to your Vercel function
return fetch(vercelFunctionUrl, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
})
.then(function(response) {
return response.json();
})
.then(function(responseData) {
console.log("Response from Vercel function:", responseData);
})
.catch(function(error) {
console.error("Fetch request failed:", error);
});
}
</script>
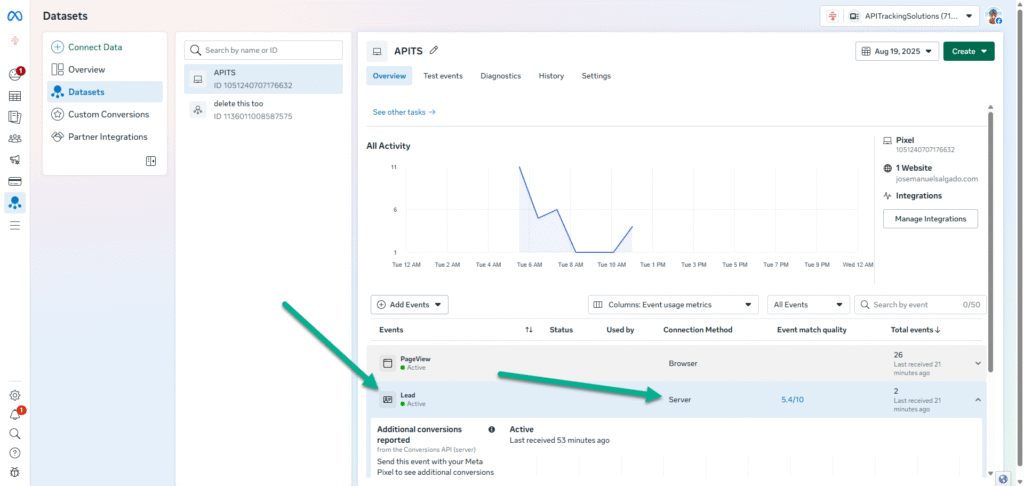
My nextJS function at vercel.com receives and formats the data, then sends the payload to my fb pixel through CAPI
// This Vercel function handles the 'OutboundClick' event for the Facebook Conversions API.
// It is a simplified version of the 'Purchase' function, as it does not need to
// interact with a third-party service like Stripe.
import crypto from 'crypto';
// Replace with your actual values from Vercel's environment variables.
// NOTE: For security, these should be set in your Vercel project settings.
const FACEBOOK_ACCESS_TOKEN = process.env.FACEBOOK_ACCESS_TOKEN;
const FACEBOOK_PIXEL_ID = process.env.FACEBOOK_PIXEL_ID;
// Function to hash the PII data.
// Although 'OutboundClick' may not contain PII, this function is kept for consistency
// and in case a 'clickId' or similar identifier needs to be hashed.
function hash(data) {
if (!data) return null;
return crypto.createHash('sha256').update(data.trim().toLowerCase()).digest('hex');
}
// Define the OPTIONS method for CORS preflight requests.
// This is necessary to allow the front-end to make POST requests from a different domain.
export async function OPTIONS() {
return new Response(null, {
status: 204,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "POST, OPTIONS",
"Access-Control-Allow-Headers": "Content-Type",
},
});
}
// Main POST function to handle the outbound click event.
export async function POST(request) {
let body;
try {
body = await request.json();
console.log("Received data for OutboundClick from front-end:", body);
} catch (error) {
return new Response(JSON.stringify({ error: "Invalid JSON in request body." }), {
status: 400,
headers: { 'Content-Type': 'application/json' },
});
}
const {
clickId,
fbclid,
fbc,
fbp,
clientUserAgent,
sourceUrl
} = body;
// The check for 'clickId' has been removed. The function will now proceed
// whether or not this ID is provided by the front-end.
try {
// --- STEP 1: CONSTRUCT THE FACEBOOK CAPI PAYLOAD ---
// This payload is simpler than the 'Purchase' event as it doesn't
// contain financial or product information.
const facebookEventData = {
data: [{
event_name: 'OutboundClick',
event_time: Math.floor(Date.now() / 1000),
event_source_url: sourceUrl,
action_source: 'website',
user_data: {
// Use client data for better attribution and deduplication
client_ip_address: request.headers['x-forwarded-for'] || request.headers['x-real-ip'] || request.ip,
client_user_agent: clientUserAgent,
// Use cookies for deduplication
fbc: fbc,
fbp: fbp,
},
custom_data: {
// Use the unique click ID for event tracking and debugging
},
}],
// Use this optional parameter to ensure your events are deduplicated correctly
test_event_code: null // Use 'TESTxxxx' from your Events Manager for testing
};
// --- STEP 2: SEND DATA TO FACEBOOK CAPI ---
const fbEndpoint = `https://graph.facebook.com/v20.0/${FACEBOOK_PIXEL_ID}/events?access_token=${FACEBOOK_ACCESS_TOKEN}`;
const fbResponse = await fetch(fbEndpoint, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(facebookEventData),
});
const fbResponseData = await fbResponse.json();
if (fbResponse.ok) {
console.log("OutboundClick event sent to Facebook successfully:", fbResponseData);
} else {
console.error("Failed to send OutboundClick event to Facebook:", fbResponseData);
}
// --- STEP 3: RESPOND TO FRONT-END ---
return new Response(JSON.stringify({
message: 'OutboundClick event processed and sent to Facebook',
facebookResponse: fbResponseData
}), {
status: 200,
headers: {
"Access-Control-Allow-Origin": "*",
'Content-Type': 'application/json'
},
});
} catch (error) {
console.error("Error in CAPI OutboundClick function:", error);
return new Response(JSON.stringify({ error: error.message }), {
status: 500,
headers: {
"Access-Control-Allow-Origin": "*",
'Content-Type': 'application/json'
},
});
}
}
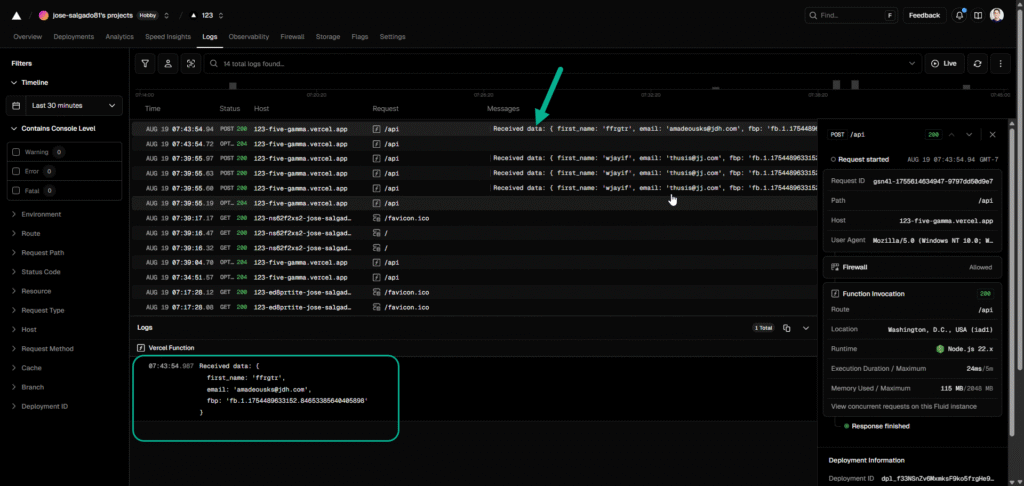
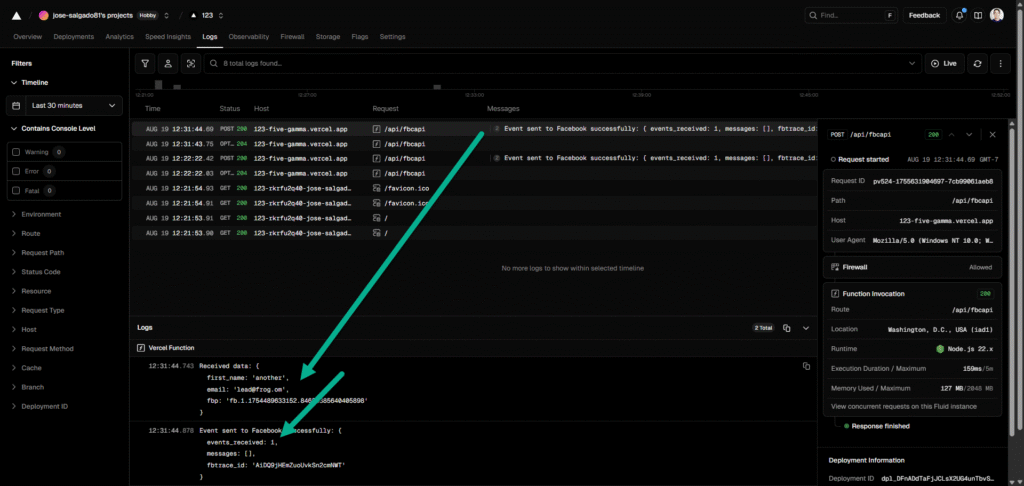
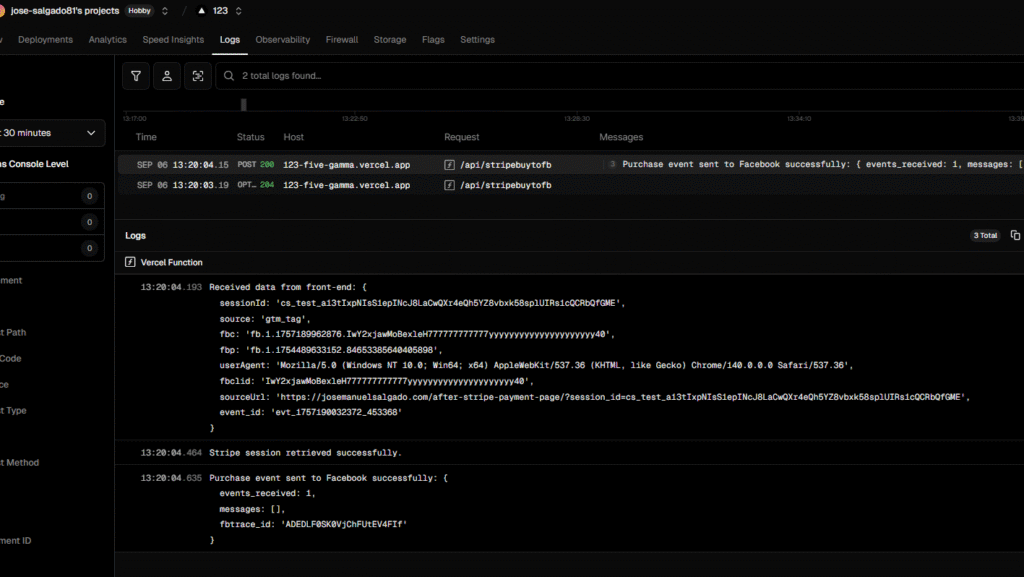
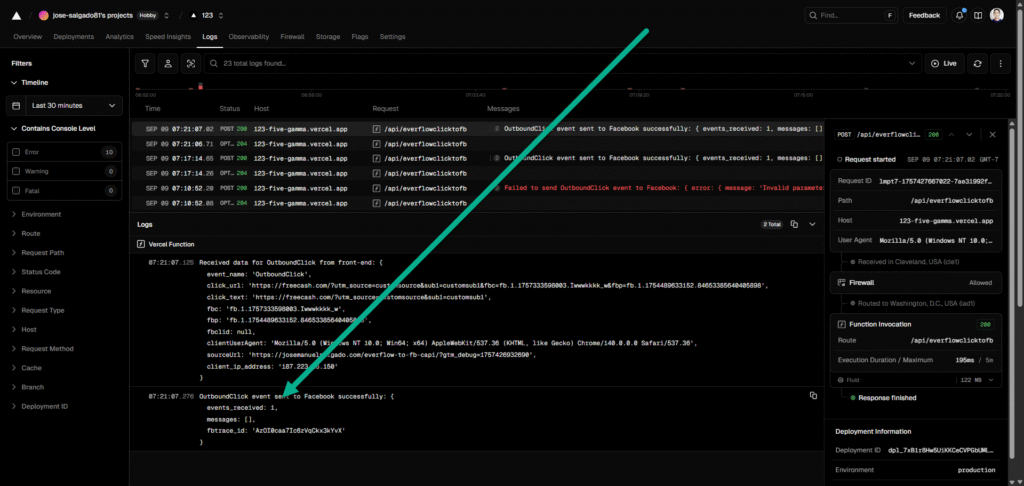
I receive 2 answers one confirms data received at vercel:
Received data for OutboundClick from front-end: {
event_name: 'OutboundClick',
click_url: 'https://freecash.com/?utm_source=customsource&sub1=customsub1&fbc=fb.1.1757333598003.Iwwwkkkk_w&fbp=fb.1.1754489633152.84653385640405898',
click_text: 'https://freecash.com/?utm_source=customsource&sub1=customsub1',
fbc: 'fb.1.1757333598003.Iwwwkkkk_w',
fbp: 'fb.1.1754489633152.84653385640405898',
fbclid: null,
clientUserAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36',
sourceUrl: 'https://josemanuelsalgado.com/everflow-to-fb-capi/?gtm_debug=1757426932690',
client_ip_address: '187.223.18.150'
}and finally FB API confirms event reception
OutboundClick event sent to Facebook successfully: {
events_received: 1,
messages: [],
fbtrace_id: 'AD7Vm2FF1BhLuOWS55QGYAY'
}
Available for hire. If you want me to implement this automation for your business (or if you want a guided demo)